In this work, we introduce ReactDance, a novel diffusion framework operating on a hierarchical latent space.
Our approach tackles fine-grained spatial interactions challenge by disentangling coarse body postures from high-frequency motion dynamics through Hierarchical Finite Scalar Quantization (HFSQ),
and ensures efficient, coherent long-form generation via a non-autoregressive Blockwise Local Context (BLC) sampling strategy.
Method
Hierarchical Finite Scalar Quantization (HFSQ)
ReactDance proposes a multi-scale motion representation HFSQ that effectively disentangles coarse body posture from high-frequency dynamics.
This further allows for a layered guidance mechanism,
enabling the model to prioritize global synchronization while maintaining high-fidelity spatial expression
in extremities, which is crucial for authentic reactive performances.
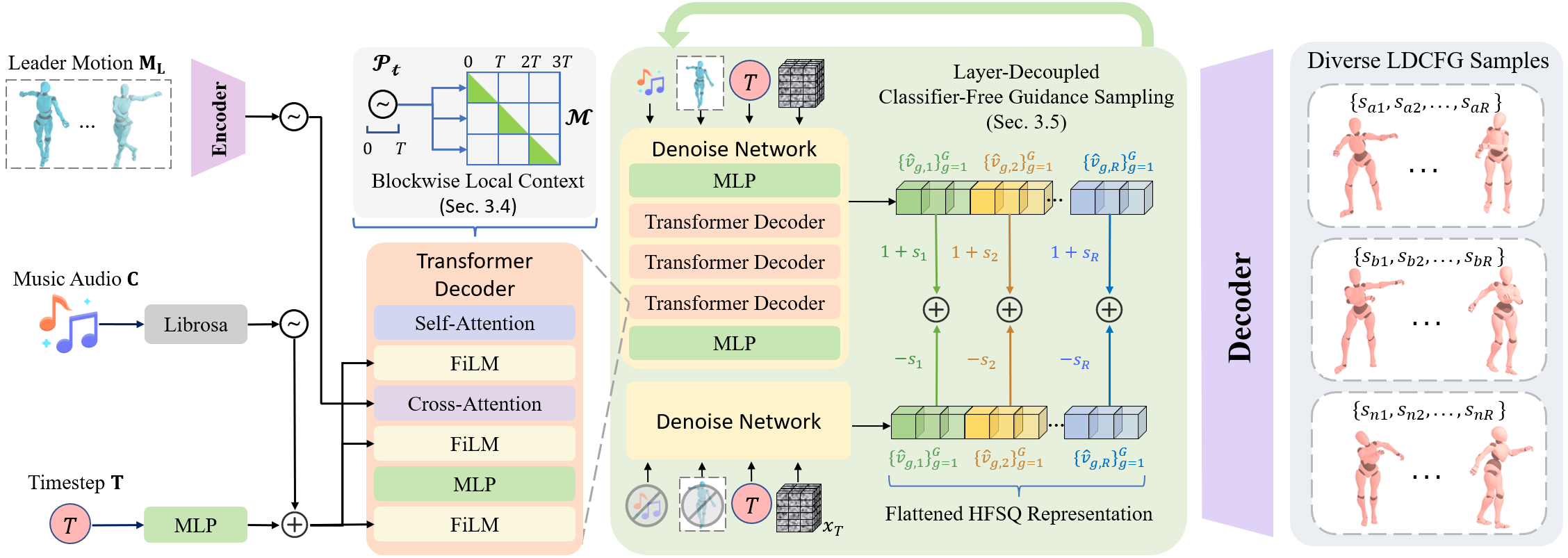
ReactDance Pipeline
Overview of the complete ReactDance pipeline architecture.
Coherent Parallel Sampling
The coherent parallel sampling is enabled by the interplay between the Dense Sliding Window (DSW) training strategy and the Blockwise Local Context (BLC ) inference protocol.
Training: DSW Crosses Boundaries (Foundation of Continuity). The HFSQ decoder is trained on thousands of overlapping windows that straddle the fixed boundaries used later in inference. This effectively trains the decoder to act as a robust "kinematic smoother" for boundary regions.
Inference: BLC Protocol (Local Fidelity with Global Consistency). During inference, we generate blocks in parallel using Periodic Causal Masking (restricting attention to the local window) and Phase-aligned Positional Encoding (resetting temporal phase per block). While this protocol segments the attention context, cross-block continuity is effectively preserved by the DSW-trained decoder, which stitches the boundary latents of Block and into smooth transitions.
Comparison
Qualitative comparison with baselines.
More Results
Diversity
ReactDance generates diverse dance movements for the same input leader motion and music.
HFSQ Layerwise Reconstruction
Visualization of HFSQ's multi-layer motion representation showing how different scales contribute to the final motion.
Layer-Decoupled Classifier-Free Guidance (LDCFG)
During inference, LDCFG applies independent guidance strengths to each layer of the predicted latent. This strikes a more fine-grained control over high-frequency interaction details and the global kinematic structure.
Since ReactDance use three independent HFSQs for upper limb motion, lower limb motion and relative root distance, LDCFG allows for separate control over the spatial expression of each body part, enabling more precise and customizable reactive dance generation.
LDCFG for upper limb motion.
LDCFG for lower limb motion.
LDCFG for both upper and lower limb motion.
LDCFG for limb motion and global movement.
Out-of-Distribution (OOD) Generalization
ReactDance's robustness on challenging out-of-distribution scenarios with different movement types and body dynamics. Here we present four representative OOD cases from FineDance Solo Dataset that test the model's ability to generalize beyond the DD100 training set distribution, demonstrating its adaptability and robustness in generating coherent and high-fidelity reactive dance movements under diverse conditions.
Upper Limb Spatial Alignment (OOD1): ReactDance effectively generates precise upper limb movements that maintain spatial coherence with the leader's motion, even when the follower needs to execute fine-grained hand and arm placements.
Synchronized Spinning (OOD2): Our method handles complex rotating movements, maintaining synchronization with the leader's motion while generating coordinated rotational dynamics for the follower.
Rhythmic Accompaniment (OOD3): ReactDance generates follower movements that are tightly synchronized with the music rhythm, creating coherent rhythmic accompaniment to the leader's dance.
Large Pose Adaptation (OOD4): Our method successfully adapts to significant body pose changes including deep bends and unusual postures, maintaining coherence and responsiveness to the leader's motion.
Swap Duet
Demonstration of role swapping where the follower becomes the leader and vice versa, showing ReactDance's flexibility in handling different interaction patterns.
Hand Modeling
Hand and finger dynamics for detailed hand-to-hand interactions in dance movements. Compared to Duolando, ReactDance achieves more aligned duet dance interaction.
Citation
BibTeX Citation:
@inproceedings{
lin2026reactdance,
title={ReactDance: Hierarchical Representation for High-Fidelity and Coherent Long-Form Reactive Dance Generation},
author={Jingzhong Lin and Xinru Li and Yuanyuan Qi and Bohao Zhang and Wenxiang Liu and Kecheng Tang and Wenxuan Huang and Xiangfeng Xu and Bangyan Li and Changbo Wang and Gaoqi He},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=FvMyAMbbX0}
}